Ontopavese
The Ontology
OntoPavese in a nutshell
The formal ontology OntoPavese aims to represent the works of Cesare Pavese in both breadth and depth by structuring the available knowledge within a rigorous semantic hierarchy. It encompasses all published works, both poetry and prose, as well as private documents such as letters and diaries, and archival data. In this way, it builds a coherent network of bibliographic, philological, and archival information aligned, on one side, with the IFLA Library Reference Model (LRM) and its related formal ontology, LRMoo, now incorporated into CIDOC-CRM, and, on the other side, with the Records in Contexts (RiC) model developed by the ICA and its ontology, RiC-O. In short, the LRM model distinguishes three main levels of a work: Work, the work as an idea; Expression, the text or version of the work; Manifestation, the physical edition in which that text is published.
At present, the dataset includes the complete primary bibliography of works written by Pavese, along with the major re-editions. For the most significant works, information is available on individual poems, chapters, and dialogues, including details on language, translations, sections, pages, dates of creation, and links to the digital annotated edition of Pavese In Testo.
Letters, diary pages, and essays are also modeled based on data extracted from XML-TEI encodings, in their current project state (February 2026), with metadata on author, related work, language, place, creation time spans, sender, and recipient.
Completing the framework are archival data concerning the handwritten drafts of the poems from Lavorare Stanca (1936), including signatures, location, and versions.
OntoPavese not only makes this data accessible but also enables researchers to query it through a search tool designed to reveal new connections and inspire new questions.
What is a formal ontology?
To understand how OntoPavese makes it possible to bring out new connections and new questions, it is necessary to clarify what is meant by formal ontology. In the field of computer science, this term refers to a representation of a given domain of knowledge (in our case, Pavese’s work) through the entities that belong to it, along with their characteristics and the relationships that link them. More precisely, an ontology allows us to define the type of an object (the class to which it belongs) and its properties. For example, among the classes that might be useful for OntoPavese are publishing houses and the books they publish. And since what a publishing house does is precisely to publish books, we can say that to publish is a property associated with both classes.
When this schema is “populated” (that is, filled) with data about the specific individuals we want to describe (for example, the editions of Pavese’s works), it becomes a knowledge graph: a network in which each element is connected to others through relationships. In a knowledge graph, all information takes the form of a triple: subject, predicate, and object (formally represented in the descriptive language RDF).
In the image below, we have a representation of the basic ontology just described, with the class of publishing houses and that of books connected through the property “publishes.”

We can then populate the ontology, for example, by adding Einaudi, an individual belonging to the class of publishing houses, and Lavorare stanca, an individual belonging to the class of books.

Both the subject (Einaudi) and the object (Lavorare stanca) can then be involved in other triples, within a vast network of relationships.
But let us now consider why one should use a representation of this kind instead of a more classical database organized in rows and columns.
The answer is that an ontology offers numerous advantages; to mention just a few:
- It can be easily integrated with new information.
- It handles incomplete information effortlessly. If the headquarters of a publishing house is not known, one simply does not enter it.
- It makes it possible to deduce implicit information. Ontologies can be queried with “inference engines” that make it possible—by defining rules (logical axioms)—to discover new knowledge by making implicit data explicit.
Beyond these operational features, however, the most important aspect of ontologies lies in their ability to connect with other existing information, thereby contributing to what is known as Open Science.
Indeed, every entity in an ontology is uniquely associated with an internet address (an IRI, Internationalized Resource Identifier). This characteristic, together with the fact that it can reference other ontologies that are standards in the fields of cultural heritage, archives, and literary resources, makes it possible to place OntoPavese within a broader existing network of information: the Semantic Web. This is an ecosystem of web models and standards in which resources are described and linked to one another in a formal way so that they can be processed by automated systems. By way of example, here are some datasets that are part of the Semantic Web: Europeana, with millions of digitized books, paintings, films, and documents from European museums, archives, and libraries; GeoNames, with over 25 million names and geographic locations; dati.camera.it, containing data on members of parliament and legislative activity of the Italian Chamber of Deputies since 1848.
In other words, an ontology is not merely a technical tool for organizing data, but a conceptual infrastructure that makes information connected, expandable, and reusable over time. This ability to link different levels—texts, documents, people, places, organizations—and to integrate them with external resources transforms a simple digital archive into a true research environment.
OntoPavese is, ultimately, a digital map of Pavese’s universe: an invisible yet essential structure that turns a heritage of documents and scholarship into an explorable, queryable, and ever-evolving network of knowledge.
OntoPavese's documentation
We present here in greater detail some of the characteristics of the information that needed to be organized within OntoPavese, along with the solutions devised for its representation. Our goal was to effectively address a comprehensive list of competency questions identified together with domain experts, such as: “How many editions has a given work gone through?”; “Which works of a given genre did Pavese write?”; “Which poems are part of a given collection?”; “Which letters did Pavese write during a specific period?”
The Information to Be Represented
As previously mentioned, the available data cover a highly significant portion of Pavese’s textual output and of scholarship about him, specifically:
- All known publications of the author’s texts, whether appearing in book or periodical form, both those published during his lifetime and posthumous ones, in their first edition and, where deemed appropriate, in subsequent editions and reprints.
- All works written by Pavese, including unpublished ones, regardless of whether they were intended as private writing or for public readership.
- All of the author’s manuscripts held at the Centro Studi “Guido Gozzano — Cesare Pavese” that preserve texts from his major creative works in prose and poetry (excluding, therefore, those containing private writings, essays, and translations).
Modelling Bibliographic and Philological Information
The reference standard for describing the semantics of bibliographic information is that established by the IFLA (International Federation of Library Associations) through LRM (Library Reference Model). A formal ontology, LRMoo, has been developed for LRM, whose classes and properties extend those of the CIDOC-CRM formal ontology (itself a standard for describing information about cultural heritage objects). OntoPavese draws on several entities from LRMoo and the CIDOC-CRM ontology to describe not only the bibliographic dimension of the PAVES-e data, but also the philological one. The latter, at least with respect to our requirements, can be effectively represented using the entities defined in these models. In particular, our ontology adopts from LRMoo the classes corresponding to the four levels of abstraction that form the core of LRM, inherited from the better-known FRBR: F1_Work, F2_Expression, F3_Manifestation, and F4_Item (WEMI). The Work defines a work at its most abstract level — that of the idea or ideas it conveys. The Expression represents a particular realisation of the work through a system of signs, independent of any material form. It follows that a single Work may have multiple Expressions (for instance, all translations of a given literary text are considered distinct Expressions). The Manifestation is likewise a non-material, purely informational object; with reference to the textual domain, it represents the publications of a specific Expression of the work. Finally, instances of Manifestation — Items — are concrete objects corresponding to individual physical copies of a given publication.
A Modelling Example: Lavorare Stanca
To examine this more closely, the classes corresponding to Work and Expression allow us to model Pavese’s output from a philological standpoint with considerable expressive power. Returning to the example of the collection Lavorare Stanca, which has a complex history both in terms of the drafting of individual poems, their inclusion and arrangement within the collection, and its editorial trajectory: two substantially different versions of the collection exist — the one published in 1936 by the Solaria publishing house, and the one issued in 1943 by Einaudi. The two editions differ significantly in the poems they include (the 1936 edition had to contend with censorship enforced under Fascism), in their internal ordering, and also in their textual content, though at this level the changes are often minor. We can therefore represent Lavorare Stanca as a single Work (i.e., an instance of F1_Work), realised (via the property R3_is_realised_in) in two distinct Expressions (i.e., two instances of F2_Expression), to which the two first editions of 1936 and 1943 correspond (via the property R4i_is_embodied_in) — as do all subsequent editions that reference one or the other Expression. The collection as a Work is linked to the individual Works of the poems it comprises through the property R67_has_part, just as the individual Expressions of those poems are linked to the Expressions of Lavorare Stanca to which they belong via the property R5i_is_component_of.
Modelling a Single Work and Its Drafts
Now, if the collection took on different forms over time, the same is true of the individual poems it contains. LRM understandably allows a degree of flexibility regarding how significant a textual change must be before one can speak of distinct Expressions. Domain experts determine on a case-by-case basis when a form taken by a text may be considered a new Expression. However, it is not only the poems published in the 1936 and 1943 editions of Lavorare Stanca that underwent revision: each text exists in several manuscript and typescript drafts that sometimes differ substantially from the printed version. With respect to the manuscript texts — which fell within the scope of the information to be represented in the portal — we established that as many Expressions should be created as there are successive drafts of each poem. More precisely, to further distinguish these from Expressions corresponding to published versions, we defined internally a subclass of F2_Expression called Witness. The figure below illustrates the instantiation of the ontology with respect to Lavorare Stanca and one of the poems it contains, Ulisse.

Modelling the Position and Sections of Texts
Among the competency questions mentioned above, there arises the need to represent data relating to the position occupied by a text within a collection and its potential membership in a specific section of the work. To this end, we defined internally the class PartialEdition, which represents the texts that make up a specific publication and which allows, through the use of dedicated data properties, the inclusion of information about the page numbers on which they appear and any sections to which they belong. The Expression of a poem included in a collection is thus published (property is_embodied_in) within the Manifestation of that collection and, more specifically, is edited (property hasPartialEdition) in a part (class PartialEdition) of that volume, through which all relevant data can be retrieved. Instances of PartialEdition are linked to the corresponding instance of F3_Manifestation through another internally defined property (isPartOf).
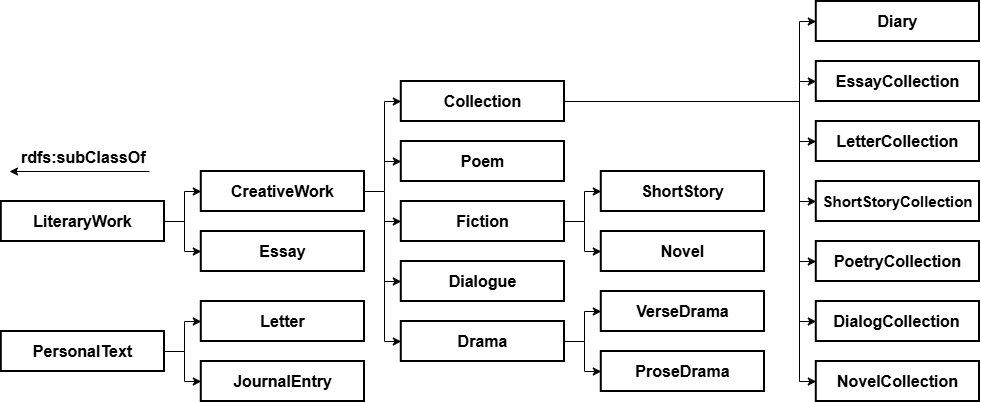
Modelling the Genre of a Work
The competency questions further require the ability to search Pavese’s output by type. This kind of information is not explicitly handled within the LRM model. We therefore articulated a system of subclasses within the F1_Work class, enabling us to distinguish first between private texts (letters and diary entries) and those intended for public readership, and then to identify within each category genres such as poetry, dialogue, short story, and so forth. The figure below offers an overview of the hierarchy as currently defined.
Modelling Archival Information
Having completed the description of the philological and bibliographic levels, it remained to select a standard for describing archival materials. We chose to adopt the authoritative standard established by the ICA (International Council on Archives) through the RiC (Records in Context) model and its associated formal ontology, RiCO. The fundamental class is RiC-E02_Record_Resource, which represents an archival resource — or rather, its informational content — in the most general sense possible. This information is considered independently of any physical manifestation (whether analogue or digital), the latter being represented instead through the class RiC-E06_Instantiation. Within Record_Resource, three subclasses are defined: RiC-E04_Record represents an informational object whose identity derives from the object itself, while a RiC-E03_Record_Set is a collection of informational objects whose identity depends on its constituent members. For our purposes — which do not currently include an exhaustive description of the archives holding Pavese’s work — the following proved essential:
- The Record_Set class, within which we developed a hierarchy of subclasses to describe archival fonds and the various sub-fonds, series, and sub-series they contain.
- The Record class, to describe individual archival folders (faldoni).
- The Record_Part class, to describe the witnesses of a work identified within a given folder.
- The Instantiation class, to describe the physical objects corresponding to such informational resources.
At this point, some clarification may be helpful. The witnesses of a work contained in a folder preserve one or more drafts of that work — drafts to which we already refer in the ontology as instances of F2_Expression. Maintaining both perspectives simultaneously — the archival and the philological — risked a significant proliferation of entities in the ontology: the same set of manuscript pages would have had to correspond to both Record_Part instances and Witness instances. We observed, however, that the nature of the Expression in the LRM model and that of the Record_Resource are closely analogous: both refer to an informational content that is independent of the material form that may carry it. Similarly, Item and Instantiation describe physical objects with comparable characteristics. We therefore considered it legitimate to describe individual manuscript drafts of works as individuals belonging to both the Witness and Record_Part classes, and their material counterparts as instances of both the Item and Instantiation classes. To our knowledge, no attempt has yet been made to harmonise the RiC model with CIDOC-CRM and LRM, and our project represents a first step in this direction.
Modelling Dates
Representing the dates on which an Expression was conceived or a Manifestation was published proved a particularly delicate task, as the available material presents a wide variety of scenarios: some dates are fully documented (day, month, and year), but more often they are only partially documented (for instance, the day and month are missing) or entirely absent. Incomplete or missing dates are in some cases uncertain; in others, the scholarly editor has reconstructed the information with a reasonable degree of confidence. To address the competency questions and the range of queries anticipated, we created three dedicated classes — Day, Month, and Year — representing the respective components of a date. An individual of the class Date — also defined internally — is linked to its components (Day, Month, Year) through properties that allow us to specify whether each is certain, reconstructed by the editor, or simply unknown. Expressions and Manifestations are always linked to their relevant creation date range through two properties: hasCreationDateFrom (start of the range) and hasCreationDateTo (end of the range). Cases in which the creation date is not a range are handled by simply treating the start and end of the range as identical objects.
Navigating OntoPavese and Metrics
OntoPavese, which is continuously updated and freely downloadable in OWL format, can be queried both through the dedicated work pages with which it is integrated, through predefined search interfaces, and via a SPARQL endpoint.
As of February 2026, OntoPavese comprises 265 classes, 932 object properties, 127 data properties, 6,356 individuals, 23,914 object property assertions, and 12,301 data property assertions. The documentation of the ontological structure can be explored using LODE (Live OWL Documentation Environment).
Examples of queries in OntoPavese
A query is a question posed to a data system: a formal way of asking, for example, “show me all works published before 1945” or “which poems were written in Turin?” Instead of manually browsing through an archive, you formulate a precise request, and the system returns exactly the information you’re looking for.
To query data such as that in OntoPavese, there is a specific language called SPARQL (SPARQL Protocol and RDF Query Language), developed and standardized by the W3C—the international consortium that defines Web standards. This is the tool used to build the preset visualizations available in the Visual Graph, and which more advanced users can use to formulate their own queries via the GraphDB SPARQL endpoint. Here, users will still find several examples of predefined queries that are useful for exploring the data.
Here are a few examples:
How to visualize OntoPavese in GraphDB
Explore OntoPavese through GraphDB: this video guides you through navigating the graph, from your first visit to the most advanced features, to discover the connections between the works, people, and places of the Pavese’s world.
For those who wish to explore further, a downloadable guide is available that provides a detailed overview of GraphDB’s features as applied to OntoPavese: from how to access the Visual Graph to predefined queries, complete with examples and references to the official documentation.